
Proyecto AWS: Aplicación serverless para convertir Texto a Audio, utilizando S3, Lambda, Polly y Python

Índice
Introducción
En este proyecto de AWS realizaremos una aplicación sin servidor que permite convertir el Texto a Audio. Para ello se utilizaran diferentes servicios de AWS como S3, funciones Lambda (con Python) y Amazon Polly.
Para llevar a cabo este trabajo simplemente requerimos de una cuenta en AWS. No es necesario pagar nada, ya que todo lo podemos hacer utilizando la capa gratuita que ofrece Amazon (siempre recuerda eliminar todo luego de finalizar el proceso).
El Proceso es el siguiente:
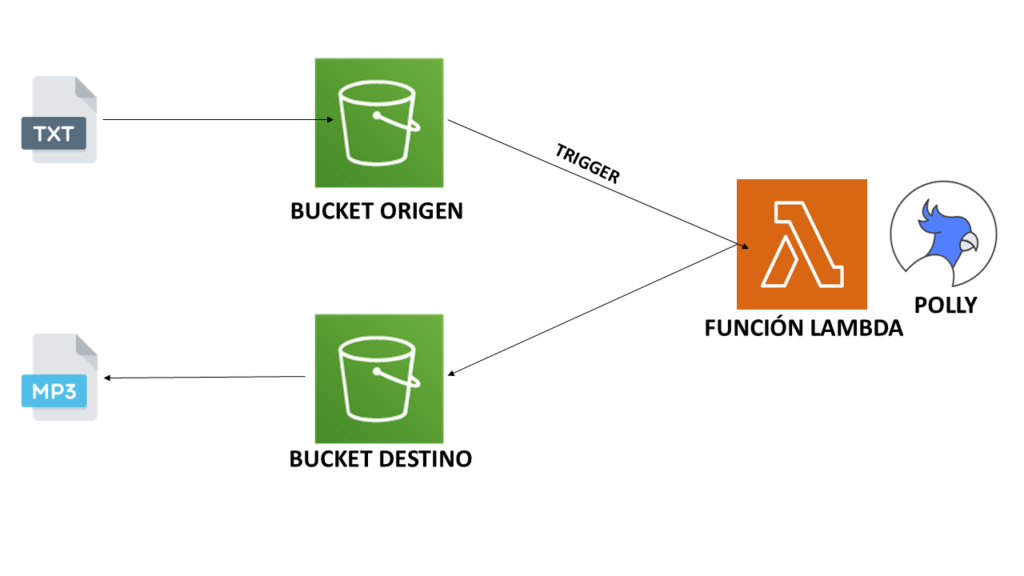
Vamos a disponer de 2 buckets en S3, uno actúa como origen (a partir de un archivo txt) y otro como destino (almacena el audio.mp3). Cuando se cargue un archivo txt en el bucket de origen, se dispara un Evento que invoca a una función Lambda (en Python con boto3). Allí se realiza el procesamiento y la conversión de texto a audio utilizando Polly. Una vez finalizado el proceso se guarda el archivo de audio en el bucket de destino.
Accede al repositorio en Github.
Paso 1: Creación de los Buckets S3
Vamos a requerir de 2 buckets en S3:
- bucket-origen-todotelco: en él se guarda el archivo en formato .txt
- bucket-destino-todotelco: luego de procesarse el archivo se va a guarda el audio en formato .mp3
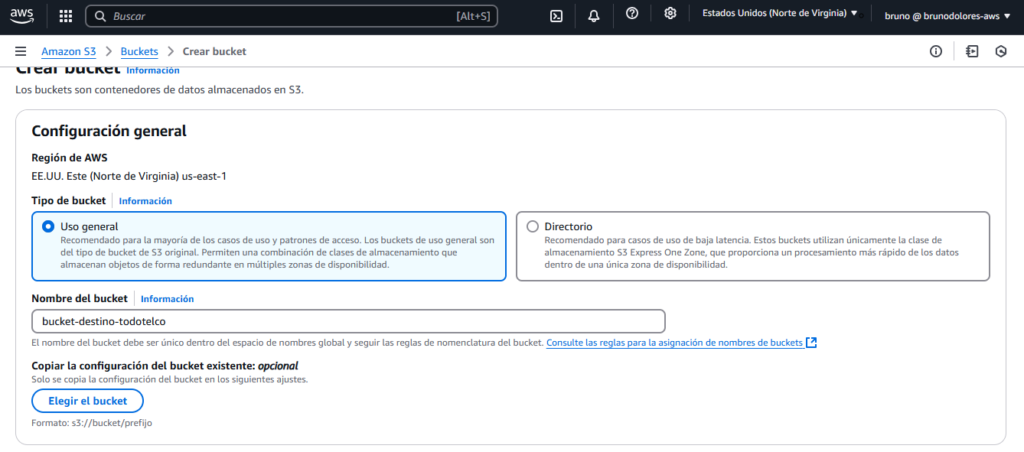
Nos dirigimos a S3 dentro de la consola de AWS y creamos los buckets:
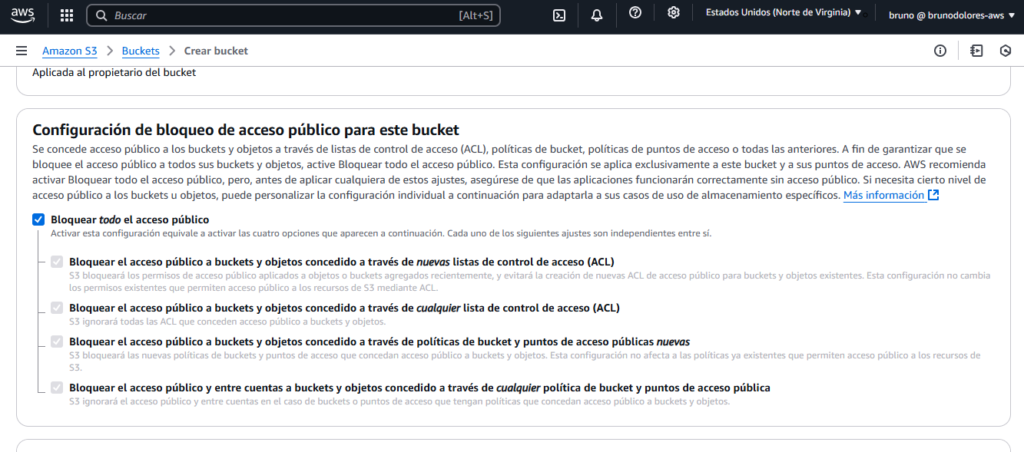
Lo dejamos en privado y habilitamos el cifrado de los datos:
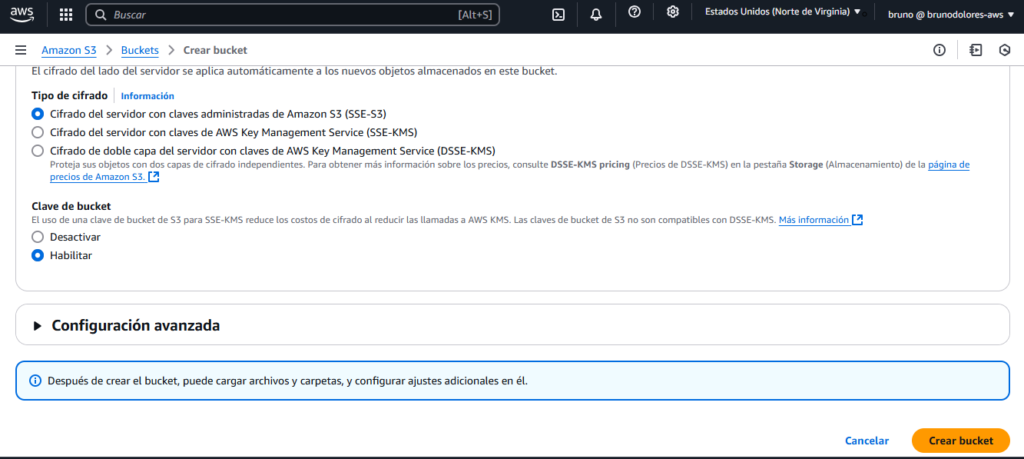
De igual manera para el bucket de origen.
Paso 2: Políticas y Roles en IAM
Necesitamos crear una política, para permitir que la función Lambda que generemos tenga acceso a obtener y crear objetos en los buckets S3 que hemos creados. Además de llamar al servicio Polly.
Agregaremos permisos en S3 de la siguiente manera:
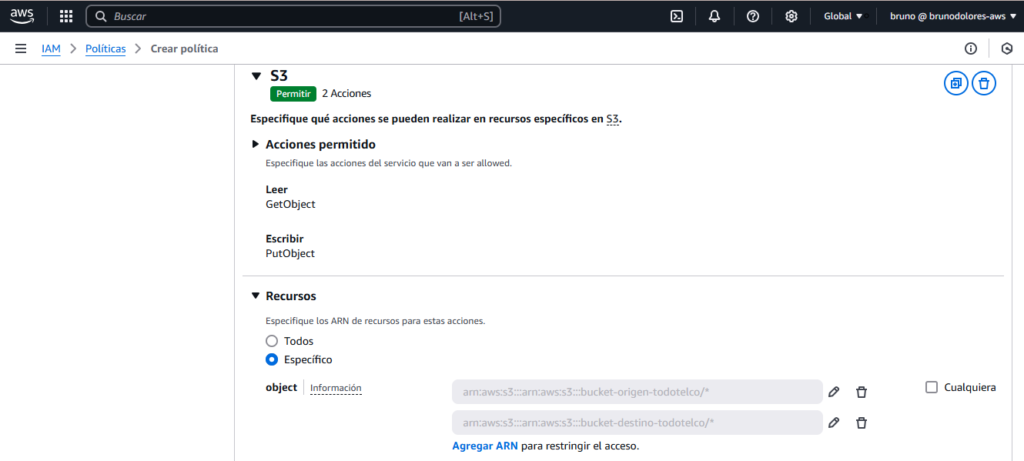
Las acciones que debemos seleccionar son GetObject y PutObject. Y en recursos debemos pegar los ARNs de los buckets que hemos creado.
Para Polly:
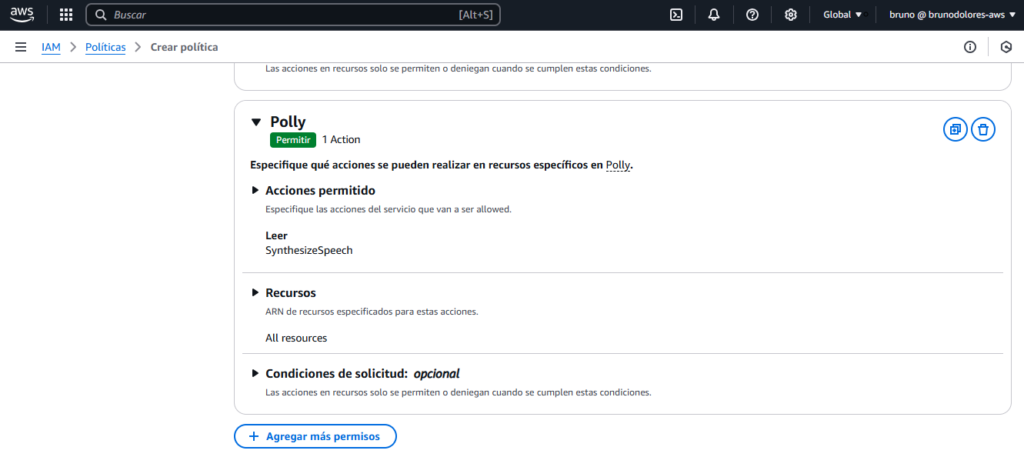
Seleccionamos la acción SynthesizeSpeech y la asignamos a todos los recursos.
Finalmente, creamos la política y la asociamos a un Rol que debemos crear:
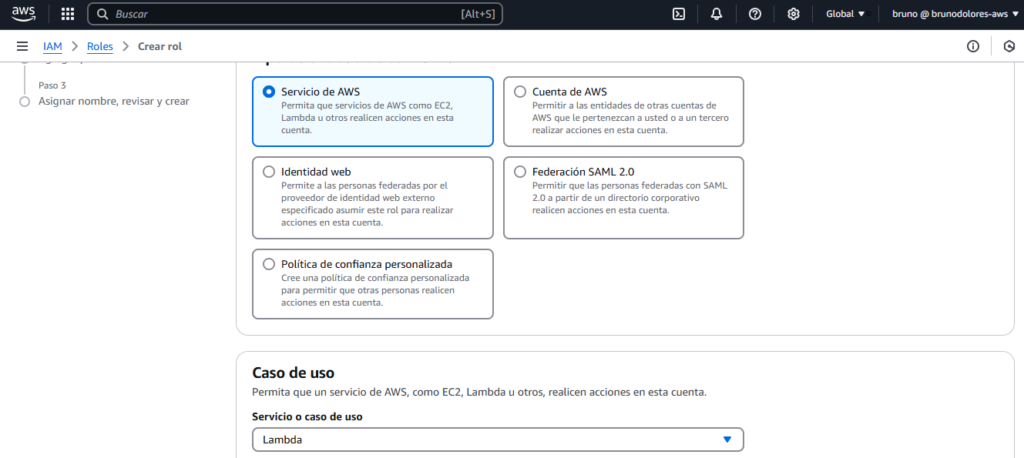
Cuando creemos el Rol, en “Servicio o caso de uso” seleccionamos Lambda, ya que es este servicio el que realiza las acciones en S3 y Polly.
En “Políticas de permisos”, asociamos la política que hemos creado arriba, y también es necesario agregar la política llamada “AWSLambdaBasicExecutionRole”. Quedando todo de la siguiente manera:
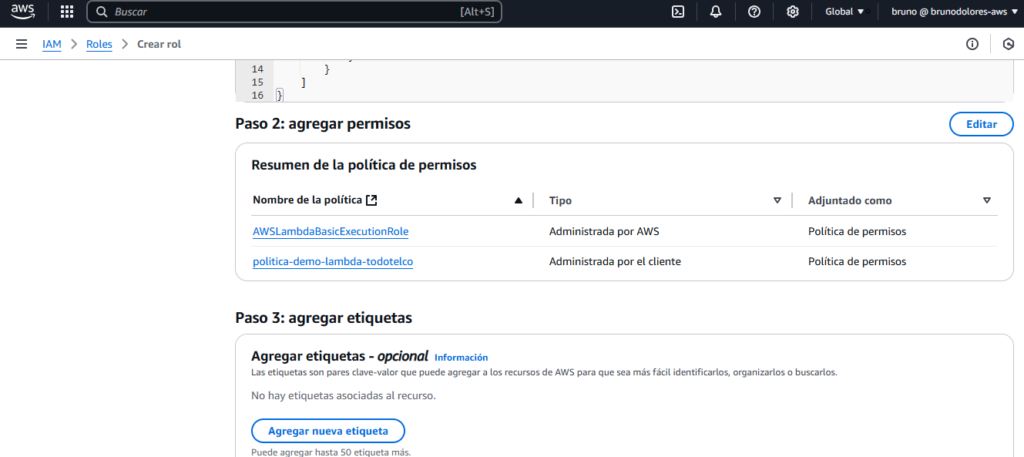
Paso 3: Función Lambda
Nos dirigimos al servicio de Lambda en AWS y creamos una nueva función con las siguientes características:
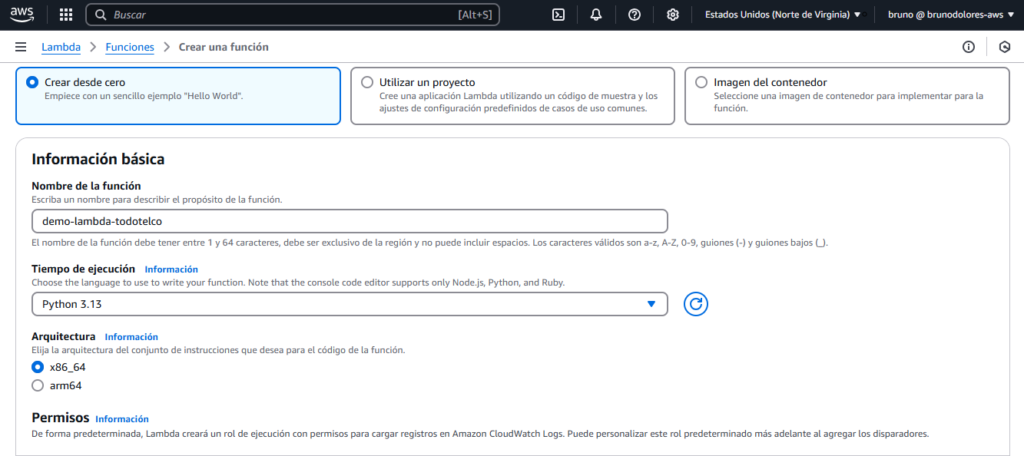
Adicionalmente, debemos seleccionar el Rol que creamos:
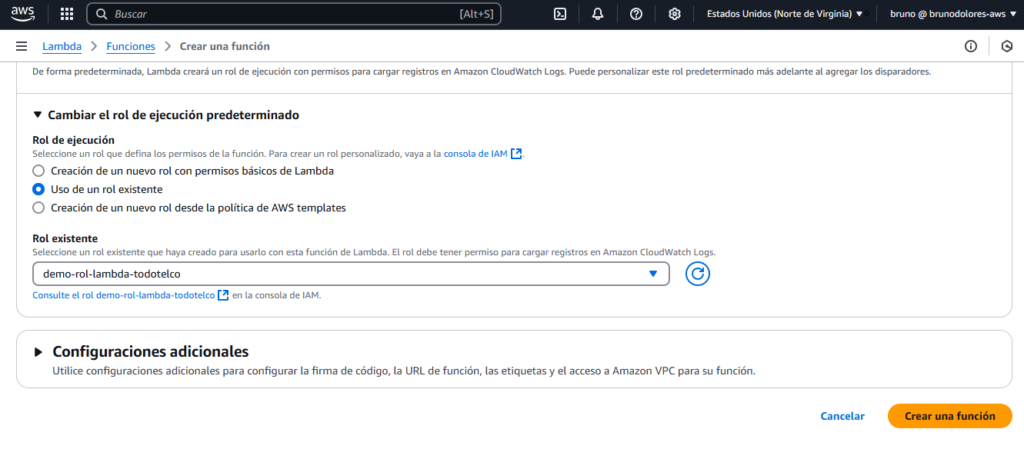
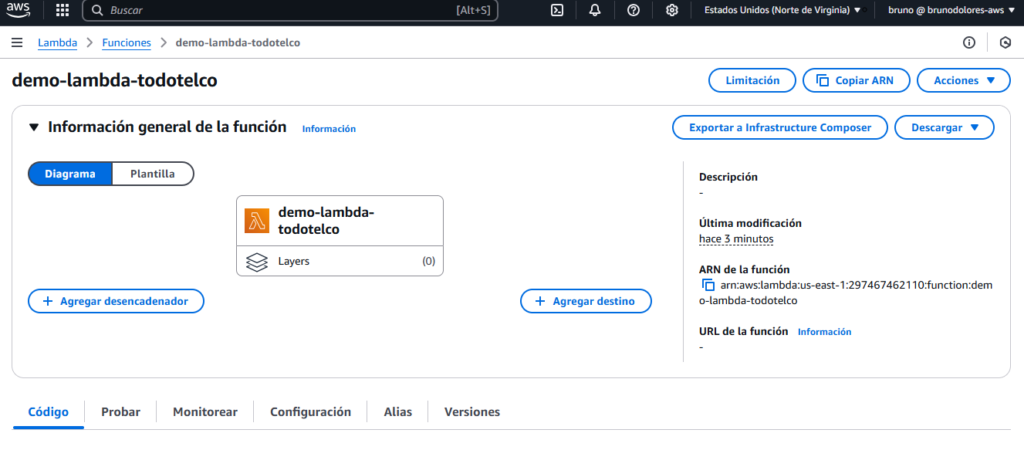
Finalmente creamos la función. Con estas configuraciones desde Lambda vamos a poder realizar acciones en los servicios de S3 y Polly, ejecutando un código de Python.
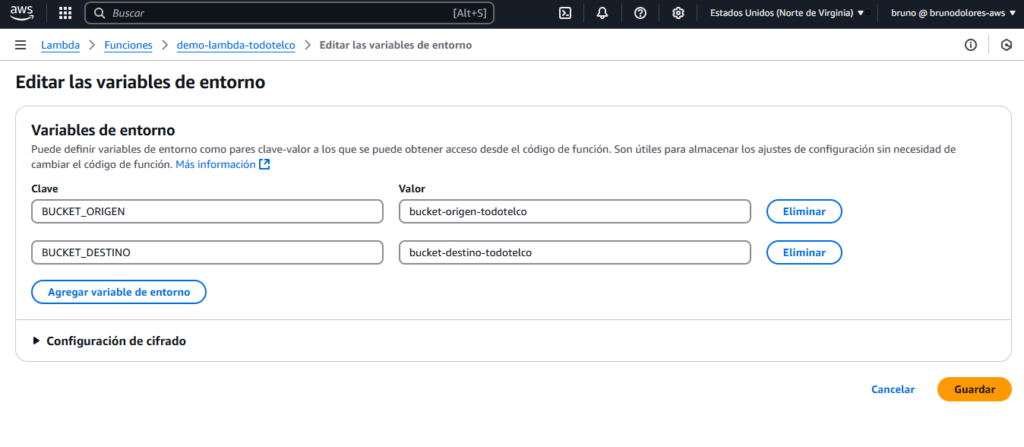
Adicionalmente, debemos agregar variables de entorno para identificar los nombres de los buckets S3 y podes obtenerlos desde el código. Para ello, vamos a “Configuraciones” –> “Variables de Entorno”.
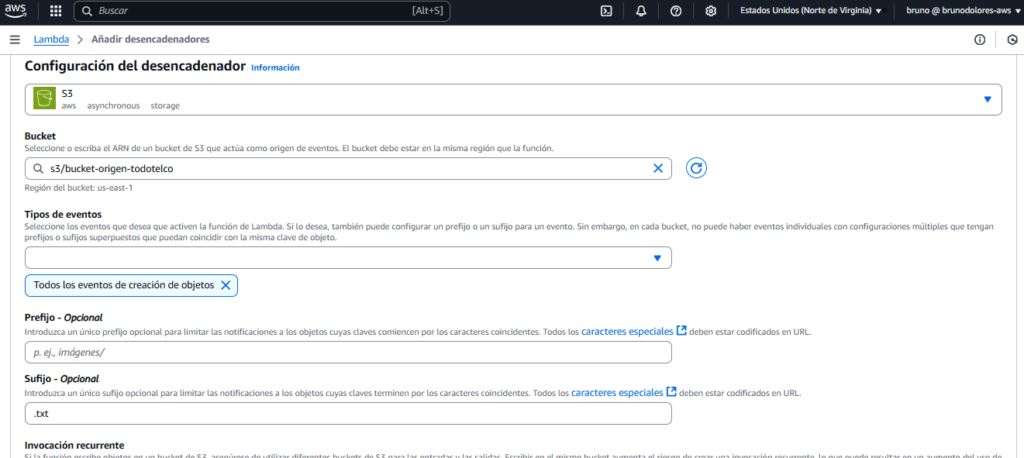
El siguiente paso es crear un evento a través de un Trigger (o desencadenador). En la misma función Lambda creada, accedemos “Agregar Desencadenador”:
Allí dentro elegimos a S3 como el servicio a detectar el evento.
Queremos detectar cuando hay algún caso de escritura de archivos, por consiguiente marcamos en “Tipos de Eventos” a “Todos los eventos de creación de objetos”.
Lo vamos a limitar solamente para los archivos de texto, por lo tanto en Sufijo establecemos la extensión “.txt”.
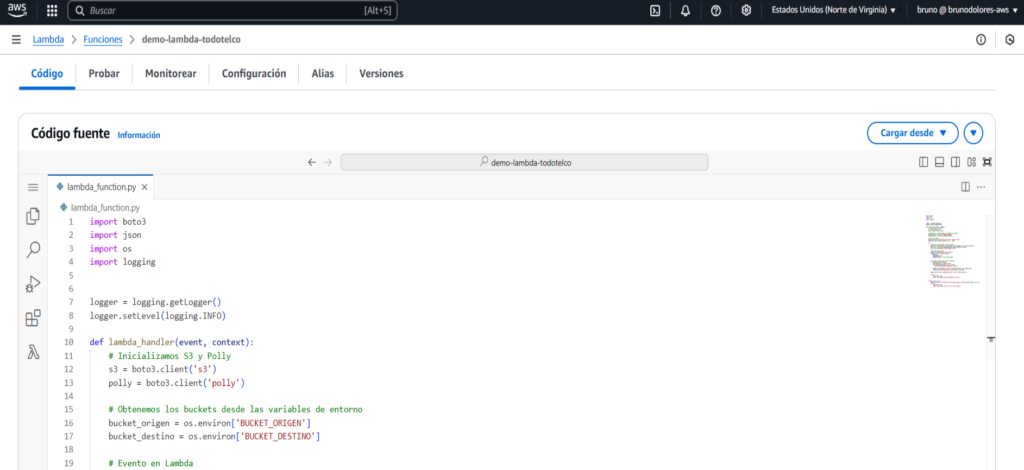
Finalmente, agregamos el siguiente código en Python. Aquí se realiza el procesamiento del archivo de texto y su conversión a audio.
import boto3
import json
import os
import logging
logger = logging.getLogger()
logger.setLevel(logging.INFO)
def lambda_handler(event, context):
# Inicializamos S3 y Polly
s3 = boto3.client(‘s3’)
polly = boto3.client(‘polly’)
# Obtenemos los buckets desde las variables de entorno
bucket_origen = os.environ[‘BUCKET_ORIGEN’]
bucket_destino = os.environ[‘BUCKET_DESTINO’]
# Evento en Lambda
text_file_key = event[‘Records’][0][‘s3’][‘object’][‘key’]
audio_key = text_file_key.replace(‘.txt’, ‘.mp3’)
try:
# Recupera el texto desde el bucket origen
logger.info(f”Obteniendo el texto desde: {bucket_origen}, key: {text_file_key}”)
text_file = s3.get_object(Bucket=bucket_origen, Key=text_file_key)
text = text_file[‘Body’].read().decode(‘utf-8’)
# Envio del texto a Polly
logger.info(f”Enviando el texto a Polly”)
response = polly.synthesize_speech(
Text=text,
OutputFormat=’mp3′,
VoiceId=’Lucia’ # voz personalizada
)
# El audio se guarda en el bucket de destino
if ‘AudioStream’ in response:
temp_audio_path = ‘/tmp/audio.mp3’
with open(temp_audio_path, ‘wb’) as file:
file.write(response[‘AudioStream’].read())
logger.info(f”Subiendo el audio en: {bucket_destino}, key: {audio_key}”)
s3.upload_file(temp_audio_path, bucket_destino, audio_key)
logger.info(f”Proceso completado para el archivo: {text_file_key}”)
return {
‘statusCode’: 200,
‘body’: json.dumps(‘Proceso completado con exito!’)
}
except Exception as e:
logger.error(f”Error procesando {text_file_key} desde el bucket {bucket_origen}: {str(e)}”)
return {
‘statusCode’: 500,
‘body’: json.dumps(‘Ocurrió un error en el proceso’)
}
Paso 4: Prueba
Una vez completados todos los pasos, verificamos si todo funciona correctamente:
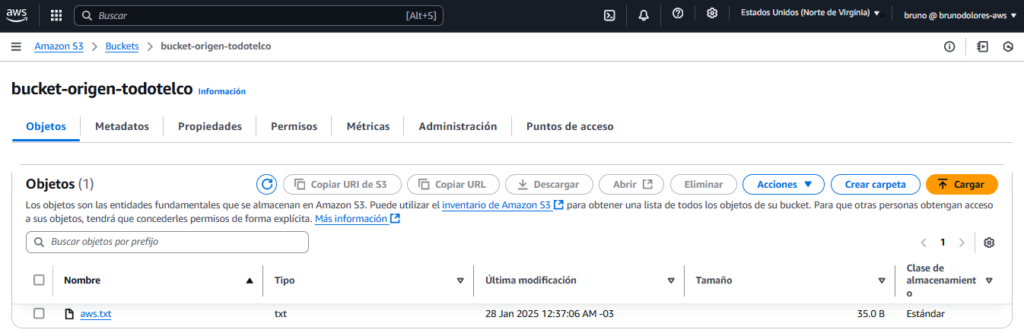
Primeramente cargamos en el Bucket Origen un archivo txt con el texto que queremos convertir a audio:
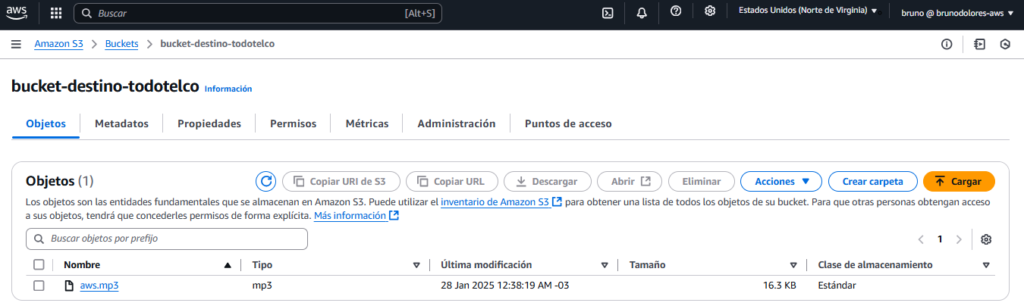
Seguidamente, luego de unos segundos vamos a visualizar en el Bucket de destino el archivo .mp3:
Si deseamos, podemos ver los LOGS de la función Lambda, desde CloudWatch. De esta forma, vemos la evolución del proceso, y si en el caso de ocurrir un error, visualizar para corregir.
Para finalizar, no te olvides de eliminar todos los recursos que hemos creado para evitar cargos extras de parte de AWS en el futuro.
Última actualización el 28-01-2025 por Bruno D’Angelo